
索引和算法
B+树
- B+树是一种平衡查找树。在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。如果用户从最左边的叶子节点开始遍历,可以得到所有键值的顺序排序。
插入操作
- Leaf Page未满,Index Page未满:直接插入即可。
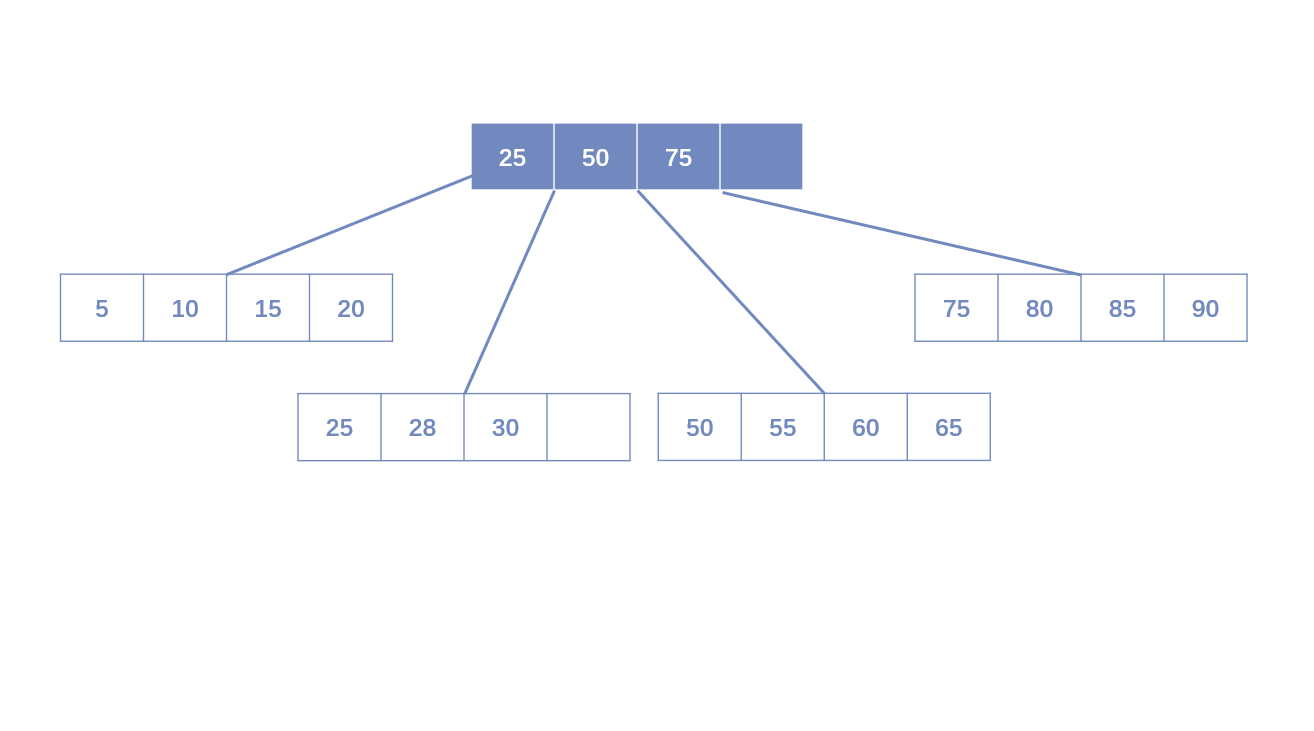
- Leaf Page已满,Index Page未满:需要拆分Leaf Page,将中间节点放入Index Page中,小于中间节点的记录放左边节点,大于或等于中间节点的记录放右边节点。
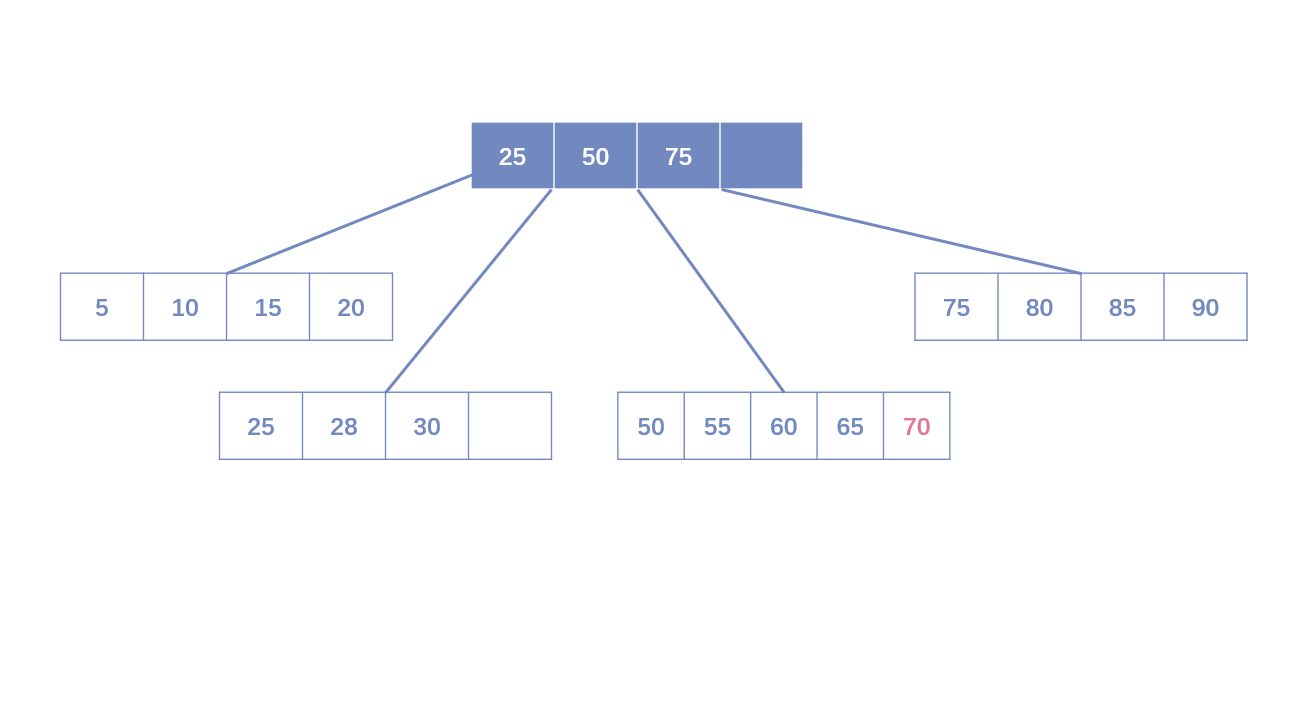
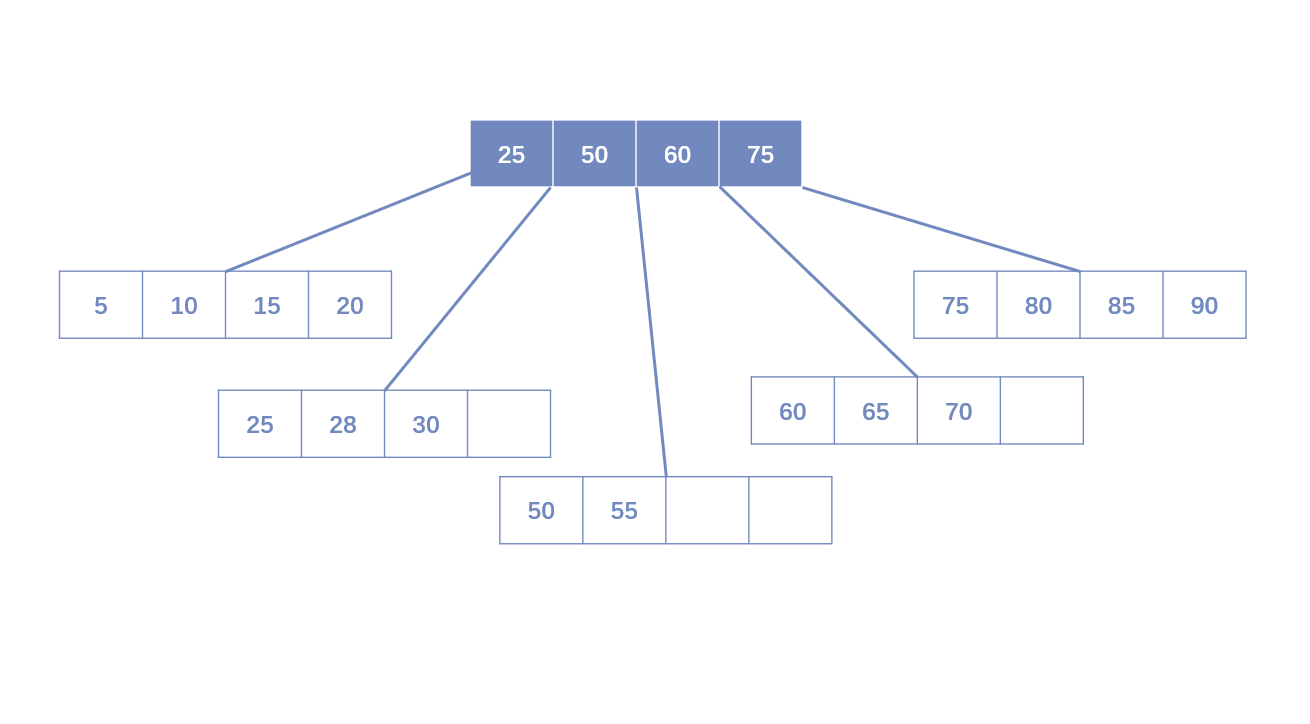
- Leaf Page已满,Index Page已满:需要拆分Leaf Page和Index Page。拆分Leaf Page同上;拆分Index Page时,小于中间节点的索引放左边,大于中间节点的索引放右边,中间节点放入上一层Index Page。
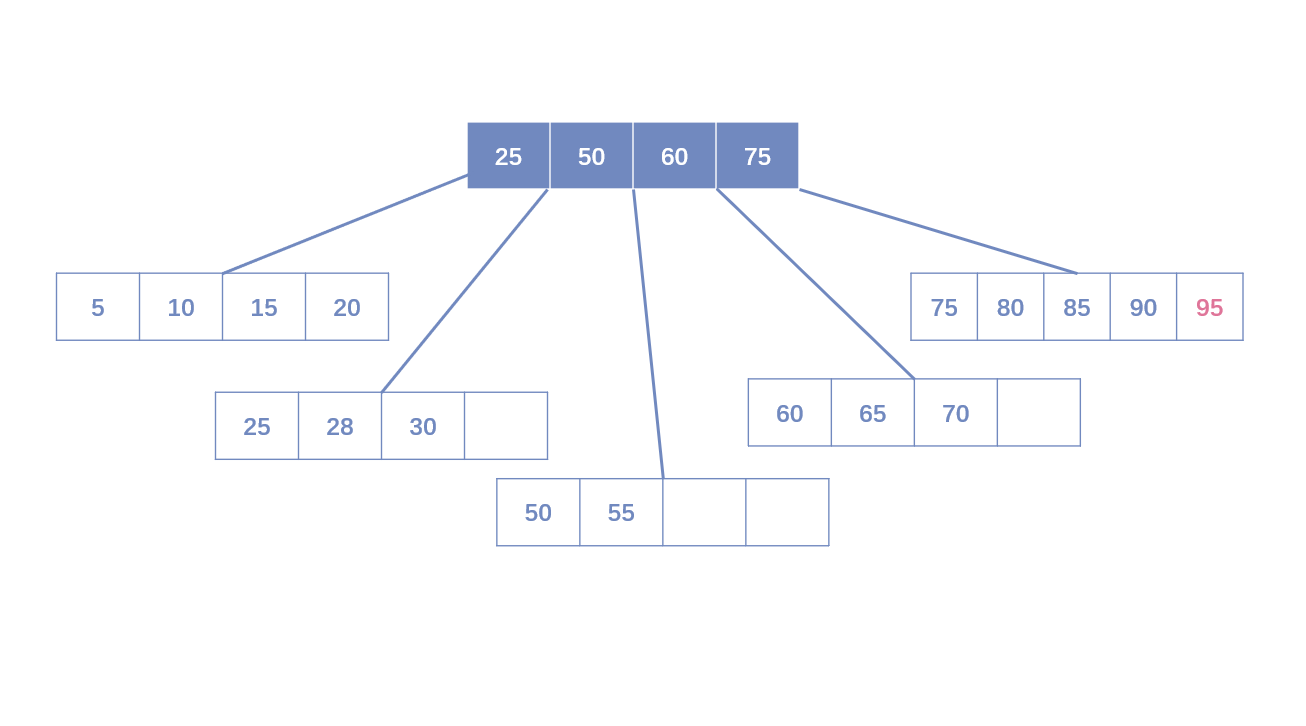
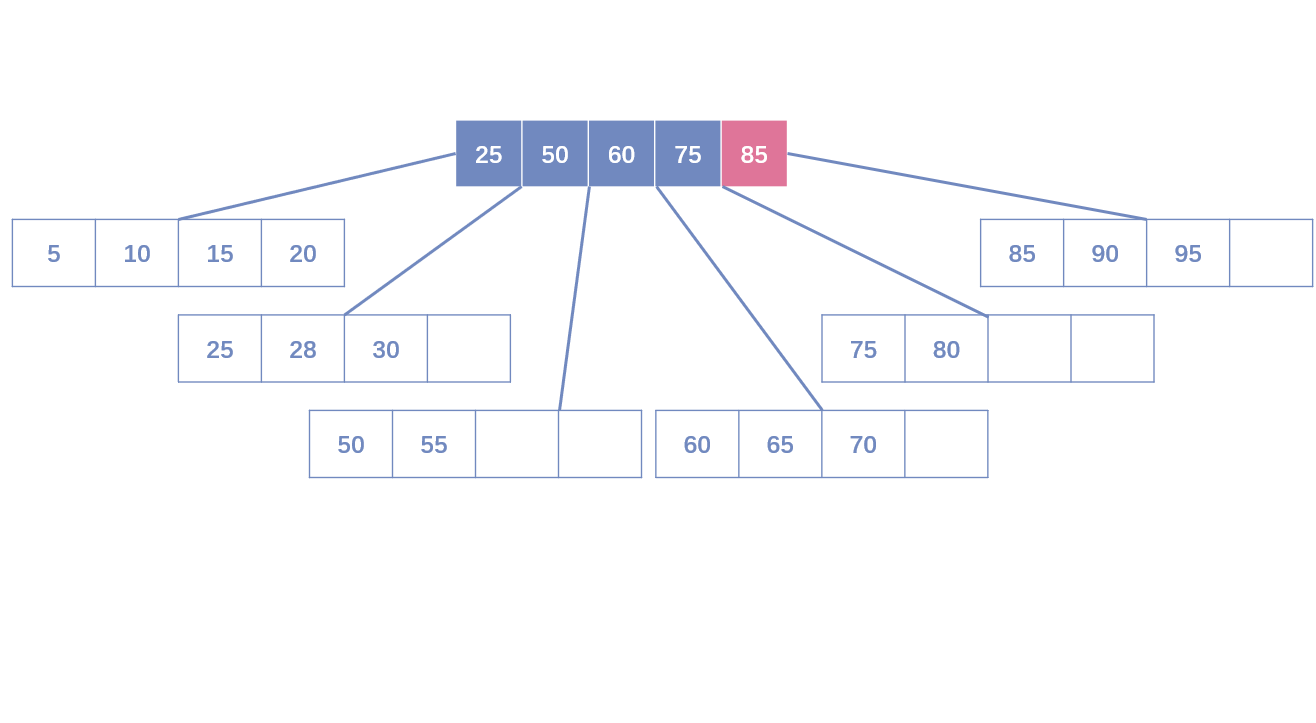
删除操作
- B+树使用填充因子来控制树的删除变化,50%是填充因子可设置的最小值。
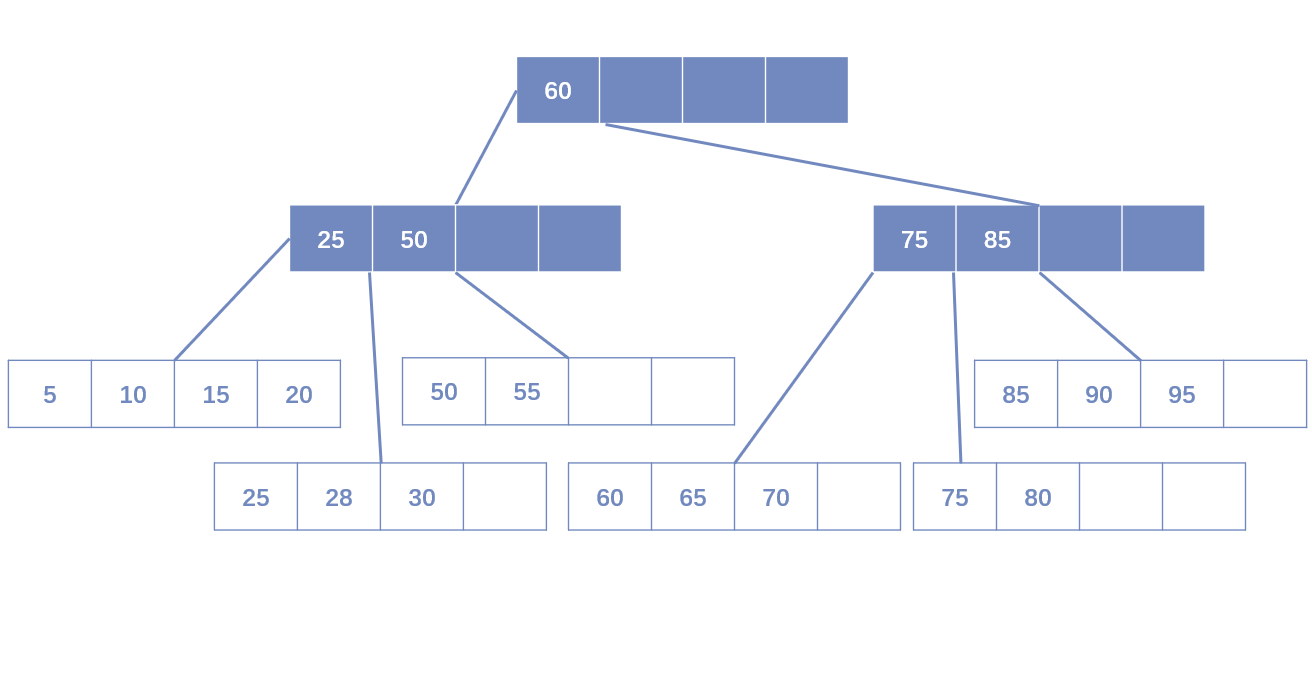
- 叶子节点和中间节点都不小于填充因子:直接删除,如果该节点还是Index Page的节点,用该节点的右节点代替。
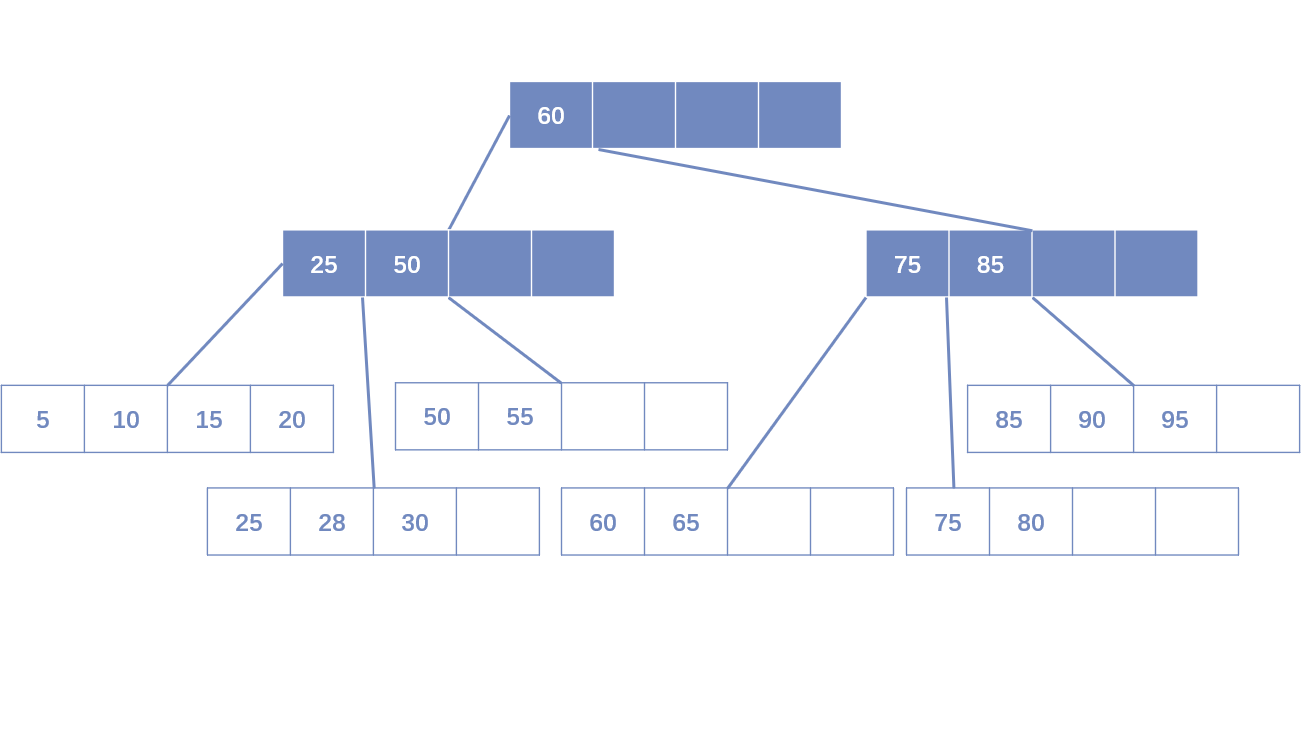
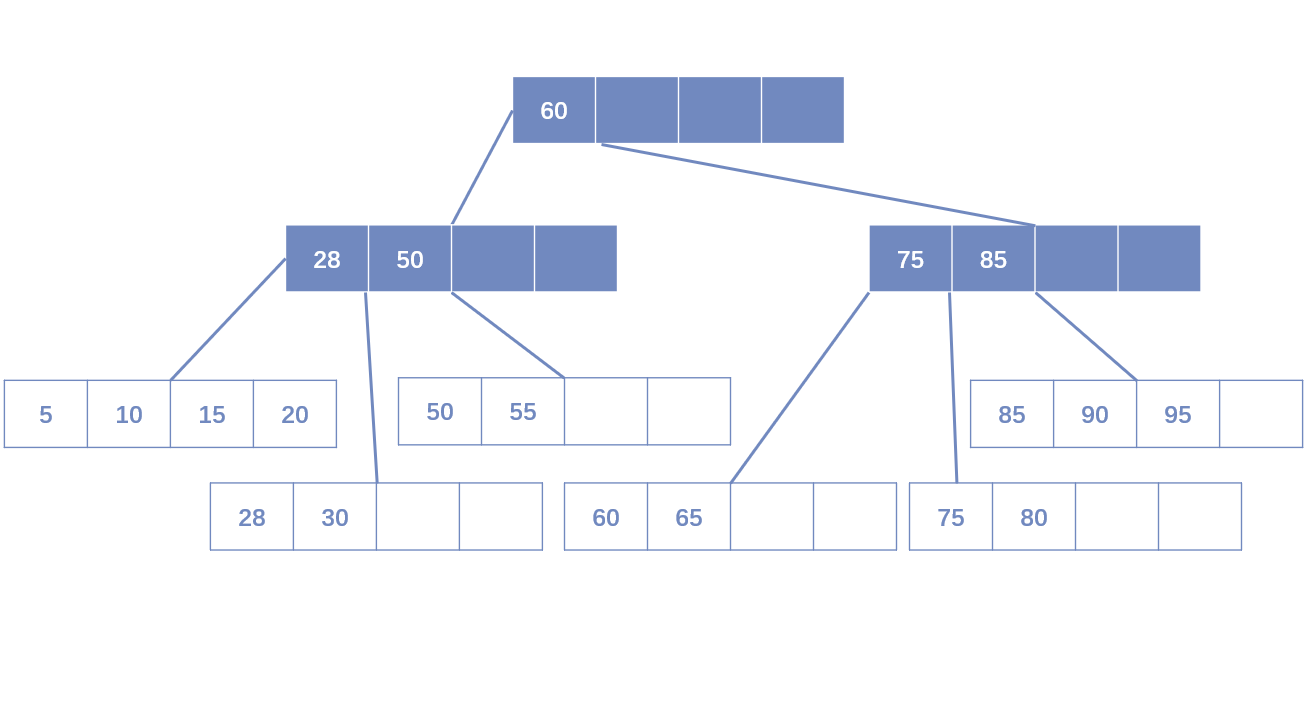
- 叶子节点小于填充因子,中间节点不小于填充因子:合并叶子节点和它的兄弟节点,同时更新Index Page。
- 叶子节点和中间节点都小于填充因子:合并叶子节点和它的兄弟节点,更新Index Page,然后合并中间节点和它的父节点、兄弟节点。
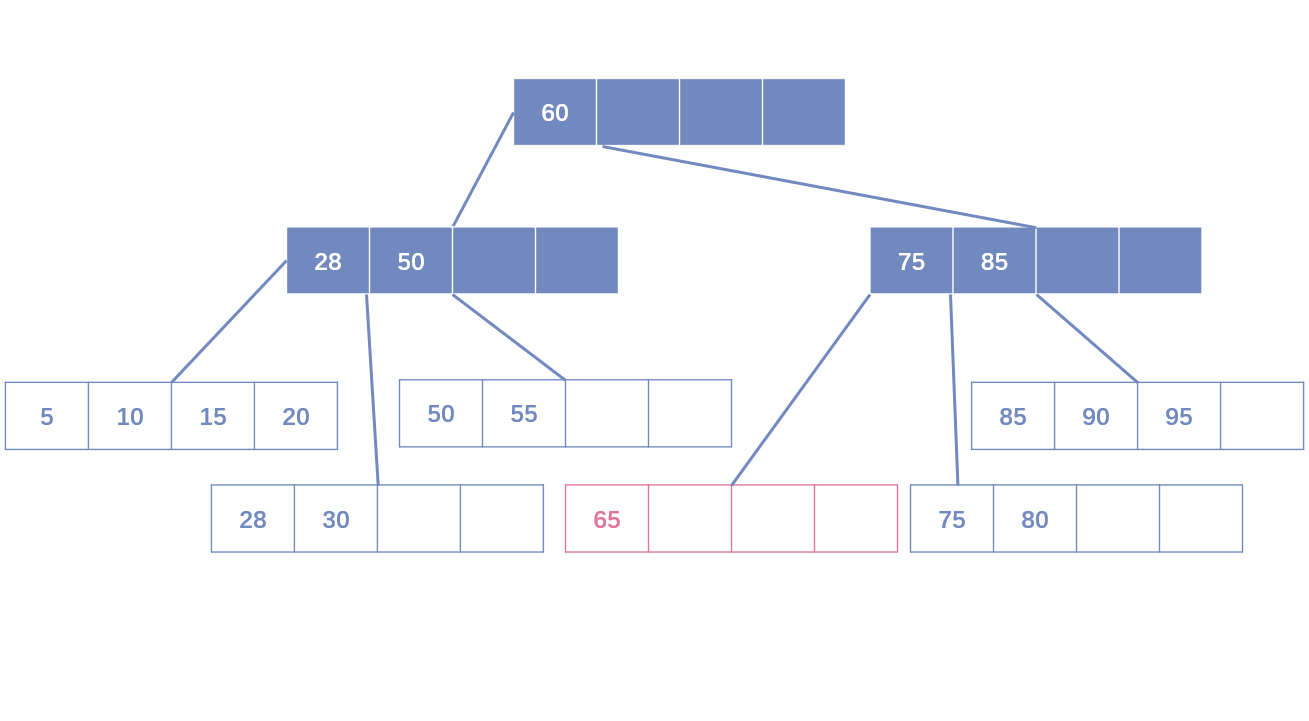

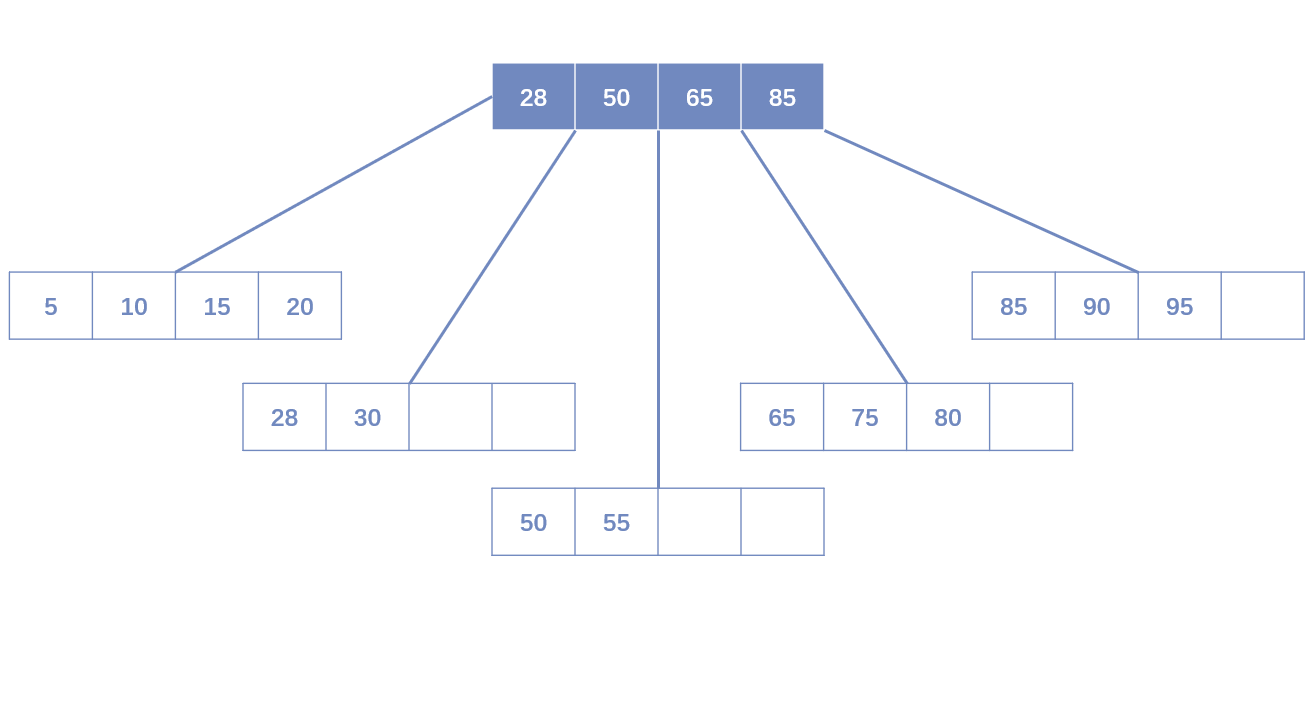
B+树索引
- B+树索引的本质是B+树在数据库中的实现。但是B+树索引在数据库中具有高扇出性的特点。因此在数据库中,B+树的高度一般都在2~4层。
扇入:指直接调用该模块的上级模块的个数。扇入大表示模块的复用程序高。
扇出:是指该模块直接调用的下级模块的个数。在此处表示向下查询次数较少。
聚集索引
- 聚集索引就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。
- 每张表有且只有一个聚集索引。在多数情况下,查询优化器倾向于采用聚集索引,因为聚集索引能够在B+树索引的叶子节点上直接找到数据。此外,由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值的查询,查询优化器能够快速发现某一段范围的数据页需要扫描。对于主键的排序查找和范围查找速度非常快。
- 聚集索引的存储并不是物理上连续的,而是逻辑上连续的。
辅助索引
- 辅助索引中,叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行还包含了一个书签,该书签用来告知InnoDB存储引擎与索引相对应行数据的位置。
Cardinality值
- 当某个字段可取值范围很小(例如性别、地区、类型等),称为低选择性,对该字段添加B+树索引是完全没有必要的。相反,如果某个字段的取值范围很广,几乎没有重复,即属于高选择性,则此时选择B+树索引是最合适的。
- Cardinality值非常关键,表示索引中不重复记录数量的预估值。在实际应用中,Cardinality / n_rows_in_table应尽可能地接近1。
B+树索引的使用
联合索引
- 联合索引是指对表上的多个列进行索引。以(a, b)为例,首先对于单列a来说,联合索引也是可以使用的,但是单独对b的查询不能使用。如果是需要对多个键进行排序,由于联合索引已经对后面的键进行了排序处理,此时使用联合索引可以减少一次排序操作。
覆盖索引
- 覆盖索引是指从辅助索引中就可以得到查询记录,而不需要查询聚集索引中的记录。辅助索引不包含整行记录的所有信息,因此其大小要远小于聚集索引,因此可以减少大量的IO操作。例如针对一些统计问题,例如count,如果表中有辅助索引,那么没有必要去查询聚集索引。
哈希算法
自适应哈希索引
- InnoDB存储引擎使用哈希算法来对字典进行查找,其冲突机制采用链表方式,哈希函数采用出发散列方式。
- 自适应哈希索引采用上述方式实现。自适应哈希索引经哈希函数银蛇到一个哈希表中,因此对于字典类型的查找非常快速。
全文检索
倒排索引
- 全文检索通常使用倒排索引来实现。它在辅助表中存储了单词与单词自身在一个或多个文档中所在的位置之间的映射。有两种表现形式:
- inverted file index,{单词,单词所在的文档ID}
- full inverted index,{单词,(单词所在文档ID,在文档中的具体位置)}
InnoDB全文检索
- InnoDB存储引擎采用full inverted index 的方式实现全文检索。为了提高检索性能,共有6张辅助表,有一个全文检索索引缓存。全文检索索引缓存是一个红黑树结构,在插入数据已经更新到了对应的表时,辅助表的数据可能还没有更新,其更新数据还在全文索引缓存中。当对全文检索进行查询时,首先会将在全文索引缓存中的数据合并到辅助表中,然后在进行查询。
限制
- 每张表只能有一个全文索引。
- 由多页组合而成的全文索引列必须使用相同的字符集与排序规则。
- 不支持没有单词界定符的语言,例如中文、日语等。