并行数据处理与性能
并行流
将顺序流转换为并行流
- 可以把流转换成并行流,从而让前面的函数归约过程并行运行。对顺序流调用
parallel()方法。
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.parallel()
reduce(0L, Long::sum);
}
- 对顺序流调用
parallel()方法不意味着流本身有任何实际的变化。它内部实际上就是设了一个boolean标志,表示让调用parallel()方法之后进行的所有操作都并行执行。类似的,对并行流调用sequential()方法就可以把它变成顺序流。不过在一个流水线中,只有最后一个parallel()或者squential()方法生效,影响整个流水线。
高效使用并行流
- 首先应该进行测量。并行流并不总是比顺序流快。
- 留意装箱。自动装箱合拆箱操作会大大降低性能。可以使用原始类型流(
IntStream、LongStream、DoubleStream)来避免这种操作。
- 有些操作本身在并行流上的性能就比顺序流差,特别是
limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。
- 要考虑流的操作流水线的总计算成本。设
N是要处理的元素总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略估计。Q值较高就意味着使用并行流时性能好的可能性比较大。
- 对于较小的数据量,选择并行流几乎不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
- 要考虑流背后的数据结构是否容易分解。例如
ArrayList的拆分效率比LinkedList高得多,因为前者不用遍历就可以平均拆分,后者则必须遍历。
- 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如一个流可以分成大小相同的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能会丢弃的元素个数却无法预测,导致流的大小未知。
- 要考虑终端操作中合并步骤的代价。如果代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超过通过并行流得到的性能提升。
分支/合并框架
- 分支/合并框架的目的是以递归的方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是
ExecutorService接口的一个实现,它把子任务分配给线程池(称为ForkJoinPool)中的工作线程。
使用RecursiveTask
- 要把任务提交到线程池,必须创建
RecursiveTask<R>的一个子类,其中R时并行化任务(以及所有子任务)产生的结果类型,或者如果任务不返回结果,则是RecursiveAction类型。要定义RecursiveTask只需要实现它唯一的抽象方法compute。这个方法同时定义了将任务拆分成子任务的逻辑,以及无法再久拆分或不方便再拆分时,生成单个子任务结果的逻辑。
class ForkJoinSumCalculator extends RecursiveTask<Long> {
private final long[] numbers;
private final int start;
private final int end;
public static final long THRESHOLD = 10_000;
public ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
private long computeSequentially() {
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
@Override
protected Long compute() {
int length = end - start;
if (length <= THRESHOLD) {
return computeSequentially();
}
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + (length >> 1));
leftTask.fork();
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + (length >> 1), end);
Long rightResult = rightTask.compute();
Long leftResult = leftTask.join();
return leftResult + rightResult;
}
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
}
使用分支/合并框架的最佳做法
- 对一个任务调用
join方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子任务的计算都开始之后再调用它。否则会比原始的顺序算法更慢更复杂,因为每个子任务都必须等待另一个子任务完成才能启动。
- 不应该在
RecursiveTask内部使用ForkJoinPool的invoke方法。相反,应该直接调用compute或fork方法,只有顺序代码才应该用invoke来启动并行计算。
- 对子任务调用
fork方法可以把它排进ForkJoinPool。同时对左右两边的子任务调用fork的效率要比直接对其中一个调用compute低。直接调用compute可以为其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销。
- 调试使用分支/合并框架的并行计算可能有点棘手,特别是查看栈跟踪无法起作用,因为调用
compute的线程并不是概念上的调用方。
- 和并行流一样,在多核处理器上使用分支/合并框架不一定比顺序执行快。分支/合并框架需要“预热”或者说要执行几遍才会被JIT编译器优化。
工作窃取
- 在理想情况下,划分并行任务时,应该让每个任务都用完全相同的时间完成,让所有的CPU内核都同样繁忙。但是实际上,每个子任务所花的时间可能天差地别,要么是因为划分策略效率低,要么是有不可预知的原因,例如磁盘访问慢,或是需要和外部服务进行协调执行。
- 分支/合并框架使用工作窃取来解决工作量不平衡的问题。在实际使用中,任务会被差不多地分配到
ForkJoinPool中的所有线程上。每个线程都为分配给它的任务保存一个双向链式队列,每完成一个任务,就会从队列头上取出下一个任务开始执行。如果某个线程早早完成了分配给它的所有任务,也就是它的任务队列已经空了,而其它的线程还很忙。这时,该线程会随机选择一个别的线程,从其队尾“偷走”一个任务。这个过程一直继续下去,直到所有的任务都执行完毕,所有的队列都清空。这就是为什么要划成许多小任务而不是少数几个大任务,这有助于更好地在工作线程之间平衡负载。
Spliterator
Spliterator,和Iterator一样用于遍历数据源中的元素,但它是为了并行执行而设计的。
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}
拆分过程
- 将
Stream拆分成多个部分的算法是一个递归过程,不断地对Spliterator调用trySplit直到它返回null。当所有的Spliterator都返回null则拆分终止。
Spliterator接口声明的最后一个抽象方法是characteristics,它将返回一个int,代表Spliterator本身特性集的编码。
| 特性 |
含义 |
ORDERED |
元素有既定顺序(例如List),因此Spliterator在遍历和划分时也会遵守这一顺序 |
DISTINCT |
对于任意一对遍历过的元素x和y,x.equals(y)返回false |
SORTED |
遍历的元素按照一个预定义的顺序排序 |
SIZED |
该Spliterator由一个已知大小的源建立(例如Set),因此estimatedSize()返回的是准确值 |
NONNULL |
保证遍历的元素不会为null |
IMMUTABLE |
Spliterator的数据源不能被修改。这意味着在遍历时不能添加、删除或修改任何元素 |
CONCURRENT |
该Spliterator的数据源可以被其他线程同时修改而无需同步 |
SUBSIZED |
该Spliterator和所有从它拆分出来的Spliterator都是SIZED |
实现自定义Spliterator
class WordCounterSpliterator implements Spliterator<Character> {
private final String string;
private int currentChar = 0;
public WordCounterSpliterator(String string) {
this.string = string;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action) {
action.accept(string.charAt(currentChar++));
return currentChar < string.length();
}
@Override
public Spliterator<Character> trySplit() {
int currentSize = string.length() - currentChar;
if (currentSize < 10) {
return null;
}
for (int splitPos = (currentSize >> 1) + currentChar; splitPos < string.length(); splitPos++) {
if (Character.isWhitespace(string.charAt(splitPos))) {
Spliterator<Character> spliterator = new WordCounterSpliterator(string.substring(currentChar, splitPos));
currentChar = splitPos;
return spliterator;
}
}
return null;
}
@Override
public long estimateSize() {
return string.length() - currentChar;
}
@Override
public int characteristics() {
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}
class WordCounter {
private final int counter;
private final boolean lastSpace;
public WordCounter(int counter, boolean lastSpace) {
this.counter = counter;
this.lastSpace = lastSpace;
}
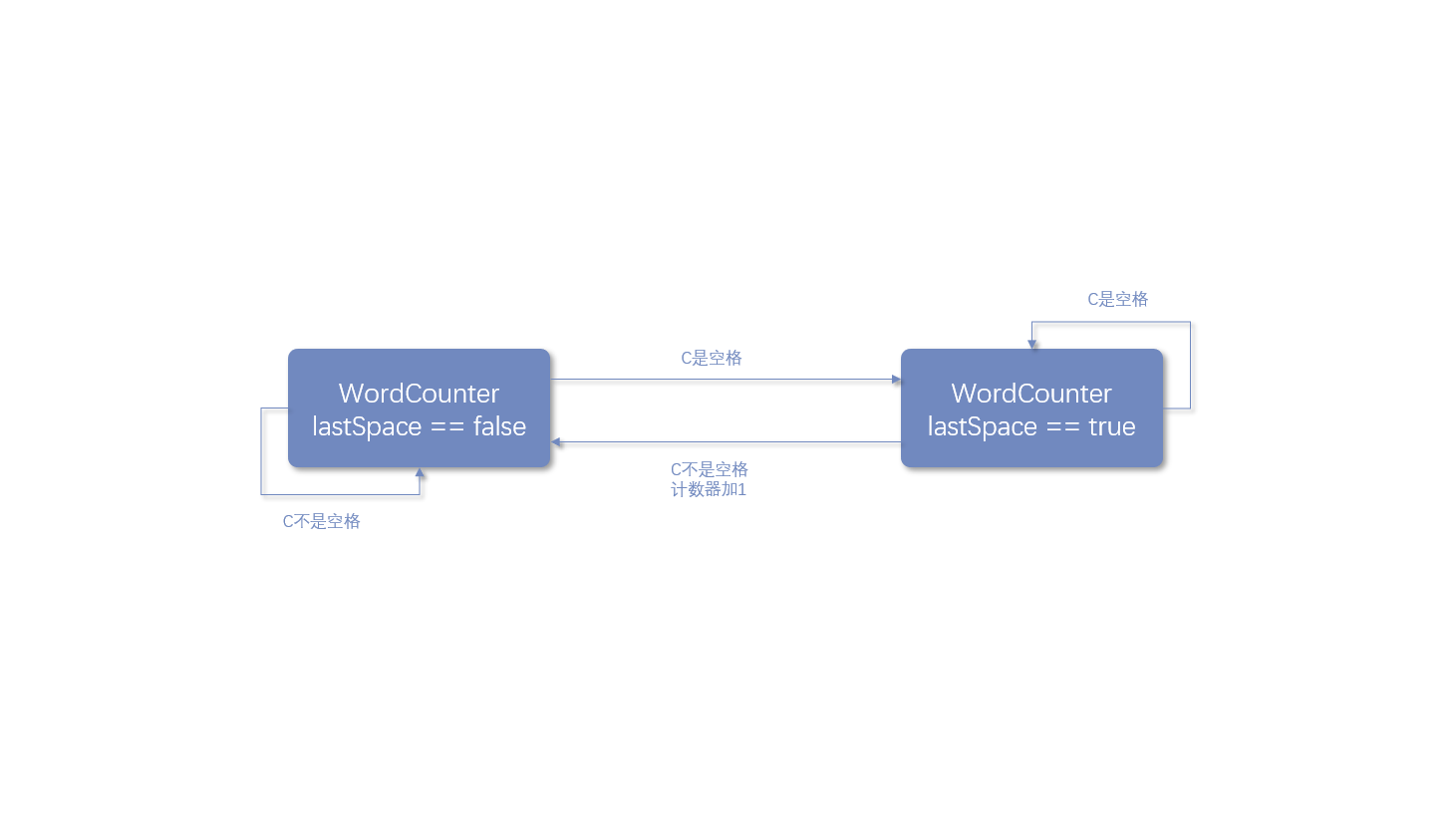
public WordCounter accumulate(Character c) {
if (Character.isWhitespace(c)) {
return lastSpace ? this : new WordCounter(counter, true);
} else {
return lastSpace ? new WordCounter(counter + 1, false) : this;
}
}
public WordCounter combine(WordCounter wordCounter) {
return new WordCounter(counter + wordCounter.counter, wordCounter.lastSpace);
}
public int getCounter() {
return counter;
}
}
public class Main {
private static int countWords(Stream<Character> stream) {
WordCounter wordCounter = stream.reduce(
new WordCounter(0, true),
WordCounter::accumulate,
WordCounter::combine
);
return wordCounter.getCounter();
}
public static void main(String[] args) {
final String SENTENCE = " Nel mezzo del cammin di nostra vita mi ritrovai in una selva oscura" +
" che la dritta via era smarrita ";
Spliterator<Character> spliterator = new WordCounterSpliterator(SENTENCE);
Stream<Character> stream = StreamSupport.stream(spliterator, true);
System.out.println("Found " + Main.countWords(stream) + " words");
}
}
tryAdvance方法的行为类似于普通的Iterator,因为它会按顺序一个一个使用Spliterator中的元素,并且还有其他元素要遍历就返回true。在上面代码中,tryAdvance将当前位置的Character传给了Consumer,并让位置加一。作为参数传递的Consumer是一个Java内部类,在遍历流时将要处理的Character传给了一系列要对其执行的函数。这里传递给了accumulate()。trySplit方法定义了拆分要遍历的数据结构的逻辑。首先要设定不再进一步拆分的下限,以避免生成太多的任务。拆分时,一旦找到合适的位置,就可以创建一个新的Spliterator来遍历从当前位置到拆分位置的子串。estimatedSize是这个Spliterator解析的String的总长度和当前遍历位置的差。
